
山石说AI|带你揭开大语言生成模型的神秘面纱
发布时间:2024-11-28 09:30分类: 无 浏览:275评论:0


【山石说AI】•第一篇
带你走进大语言生成模型的世界
探寻其背后的秘密

在这个科技飞速发展的时代,人工智能已经深入到我们生活的每一个角落。作为人工智能领域的一颗耀眼明星,大语言生成模型引起了广泛的关注。它究竟有何魅力,又是如何改变我们的生活和工作的呢?下面,让我们一起走进大语言生成模型的世界,探寻其背后的秘密。

在我们的数学世界里,有一个简单而强大的概念叫做“函数”。想象一下,你有一个公式 f(x) = ax + b,这是一个线性函数,其中 a 和 b 是固定的数字,而 x 是你可以任意选择的数字。每当你在 x 的位置放入一个数字,这个函数就会按照 a 和 b 的规则,给出一个相应的结果。比如,如果 a=2 且 b=1,那么当你输入 x=3 时,函数就会输出 f(3) = 2*3 + 1 = 7。这个过程中,a 和 b 决定了函数的形状和位置,它们是函数的关键参数。
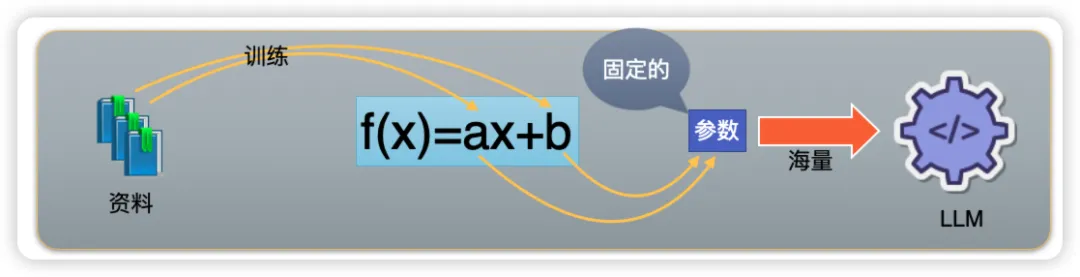
在机器学习的领域,这个概念被进一步扩展。机器学习中的模型就像是一个复杂的函数,它的任务是通过调整内部的参数(就像 a 和 b),来尽可能地拟合给定的数据样本。这些参数不是预先设定的,而是通过训练过程中不断调整的。训练的过程,实际上就是机器学习模型在寻找最合适的 a 和 b 的值,使得模型能够准确地预测或生成新的数据。
在这个简化的例子中,我们只有两个参数 a 和 b。但是,在现实世界的机器学习模型中,参数的数量可能是成千上万的。而当这些参数的数量达到上十亿、甚至百亿级别时,我们就进入了一个全新的领域——大型语言模型。这些大模型拥有极其复杂的内部结构,它们通过大量的参数(即无数的 a 和 b)来捕捉和学习语言的深层次规律。这些模型能够理解语境、生成连贯的文本,甚至模拟人类的创造力,从而在自然语言处理领域展现出惊人的能力。当我们谈论大语言生成模型时,我们实际上是在谈论一个由海量参数构成的庞大函数,它能够处理和生成人类语言的奇迹。

现在,让我们通过一个具体的例子来理解大语言模型是如何工作的。想象一下,我们正在玩一个语言的“接龙”游戏,你我说出一个句子,然后另一个人接着完成它。在这个游戏中,大语言模型就像是那个能够无限接下去的玩家。例如: 当输入“故宫在哪里?”这个问题时,大语言模型的核心任务就是预测下一个字的可能性。
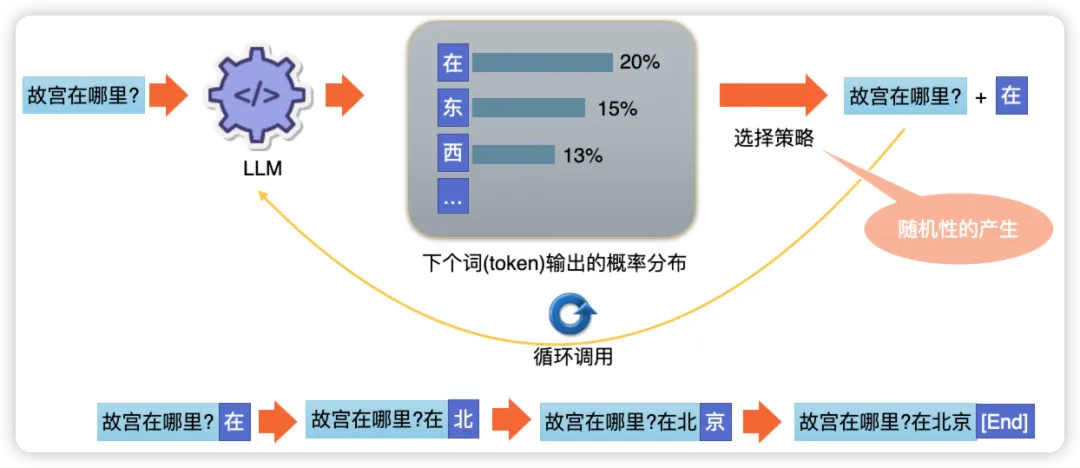
首先,我们将每个字视为一个独立的单元,也就是一个“token”。模型在接收到“故宫在哪里?”这个输入后,会为每个可能的下一个字计算一个概率分布。这个概率分布告诉我们,模型认为每个字出现在这个位置的可能性有多大。
例如,当模型处理到“在哪里”这个部分时,它可能会计算出以下概率分布:
•“在”字的概率是0.2
•“东”字的概率是0.15
•“西”字的概率是0.13
•…..
在这个概率分布的基础上,模型会采用一种选择策略,比如选择概率最高的字。因此,在这个例子中,模型选择了“北”字作为下一个字。
这个过程会不断重复,模型每次都根据当前的上下文预测下一个字的概率分布,并选择概率最高的字,直到它生成一个特殊的token——“[end]”。这个“[end]”token是一个标记,告诉模型停止生成文本。
所以,当我们输入“故宫在哪里?”时,模型可能会这样工作:
1.输入:“故宫在哪里?”
2.模型计算概率分布,选择“北”字。
3.新的输入变为:“故宫在哪里?北”
4.模型再次计算概率分布,选择“京”字。
5.重复这个过程,直到模型生成“[end]”。
最终,我们可能会得到一个完整的回答:“故宫在哪里?在北京[end]”,这时模型停止生成文本。通过这种方式,大语言模型能够一步步构建出连贯的回答。

上面我们知道了大语言模型的基本工作流程,那我们如何讲我们需要的“知识”教会大语言模型呢? 大语言模型有两种学习方法:
全量预训练:知识的全面融合
微调:特定任务的精准打击
微调是一种针对特定任务的训练方法,它通过在预训练模型的基础上调整部分参数来优化模型对特定任务的响应。这个过程可以看作是对模型进行精细化的雕刻,使其在特定领域或场景下表现得更加出色。
在微调过程中,我们通常会使用与特定任务相关的数据集来对模型进行训练。这些数据集包含了任务的特定背景知识,模型通过学习这些数据,能够更好地理解和处理相关任务。例如,如果我们想要一个模型能够更好地处理法律文档,我们就可以使用法律领域的文本数据进行微调。
然而,微调的局限性在于它的专一性。模型在微调后可能在特定任务上表现出色,但它的通用性会受到影响。微调后的模型往往只能在特定领域内保持高效,而在其他领域则可能表现不佳。

下面我们用一个例子来说明为什么大模型在学习了新的“知识”,为什么会丢失一定的通用能力。
假设我们有一个简单的线性模型 f(x) = ax + b,我们需要根据已有的数据点来训练这个模型。我们有两个数据点:(2, 6) 和 (3, 7)。
1.使用第一个数据点 (2, 6):f(2) = a * 2 + b = 6
2.使用第二个数据点 (3, 7):f(3) = a * 3 + b = 7
训练后,我们得到 a = 1 和 b = 4。
当我们微调这个模型,引入一个新的知识-数据点 (4, 13)。
我们的新方程是:
•4a + b = 13
使用之前的参数 a = 1 和 b = 4,我们得到:f(4) = 1 * 4 + 4 = 8
这显然与新的数据点 (4, 13) 不符,因此我们需要调整模型。
我们使用新数据点来重新计算 b:b = 13 - 4a b = 13 - 4 * 1 b = 9
现在我们的模型变成了 f(x) = 1x + 9。
微调后的模型 f(x) = 1x + 9 能够很好地适应新的数据点 (4, 13),但是我们需要检查它是否仍然适应旧的数据点。
对于旧数据点 (2, 6):f(2) = 1 * 2 + 9 = 11,不等于 6。
对于旧数据点 (3, 7):f(3) = 1 * 3 + 9 = 12,不等于 7。
这表明,虽然我们的模型现在适应了新的数据点,但它已经不再适应最初的数据点。这就是灾难性遗忘的例子:在微调过程中,模型为了适应新数据点而失去了对旧数据的拟合能力。

一般而言,对于大多数“静态”的知识,我们可以通过检索相关资料并将其作为提示词注入到大模型中,这一方式已成为当前主流。它简化了知识更新的过程,使得模型能够以简单、可控且高效的方式吸收和利用最新信息,从而显著提升了大模型在处理各类任务时的性能和适应性。

大语言模型的学习和适应能力是有限的,但它们在人工智能领域的应用潜力是巨大的。随着技术的不断进步,我们有理由相信,未来的研究将能够更好地解决灾难性遗忘等问题,使得大模型能够在保留旧知识的同时,更加灵活地学习新知识,为我们的生活和工作带来更多便利。通过不断的探索和创新,我们将继续推动人工智能技术的发展,让大语言模型成为连接人类与智能世界的桥梁。


标签:人工智能
- 排行