
昆仑万维方汉谈DeepSeek对英伟达的影响:短期利空、中期利好、长期利空
发布时间:2025-04-10 08:51分类: 无 浏览:230评论:0
近日,极客公园「今夜科技谈」直播间邀请极客公园创始人 & 总裁张鹏,昆仑万维 董事长兼 CEO 方汉、秘塔科技 CEO 闵可锐和清华大学交叉信息院 助理教授 吴翼,一起探讨了 DeepSeek 带来的冲击波以及 2025AI 应用还能怎么做?方汉针对DeepSeek-R1爆火背后值得关注的模型创新点、对行业的影响、DeepSeek下一步动作重点等发表了独到的见解。
看完这篇,你会对 2025 年接下来 AI 圈即将要发生的大事件,有更好的判断。

01
DeepSeek-R1:开源模型有史以来最好的成绩
张鹏:从你的角度,DeepSeek 这次爆火背后,最值得关注的创新点是什么?
方汉:最早知道 DeepSeek 是在 2022 年底、2023 年初去买卡的时候,意外得知幻方有万卡。后来注意到 DeepSeek-Coder 模型在代码类 Benchmark 上一度冲到全球第一。
再就是「推理价格屠夫」DeepSeek-V2 的推出,直接把模型推理价格打到了当时业内平均价格的 1/10。这里面有两项技术印象特别深刻,一个是 MLA(多头注意力的优化),第二个是 MTP(Multi-Token Prediction,多 token 预测)。
最近是 V3 和 R1 的推出。V3 是一个挺强的基模,但是它跟 Meta 的 Llama 405B、Qwen 等系列开源模型一样,前面还有两个天花板,OpenAI 的模型和 Anthropic 的 Claude。但是 DeepSeek-R1 这一次直接能够排到第二名的位置,开源模型有史以来最好的成绩,这是让我们最震惊的。
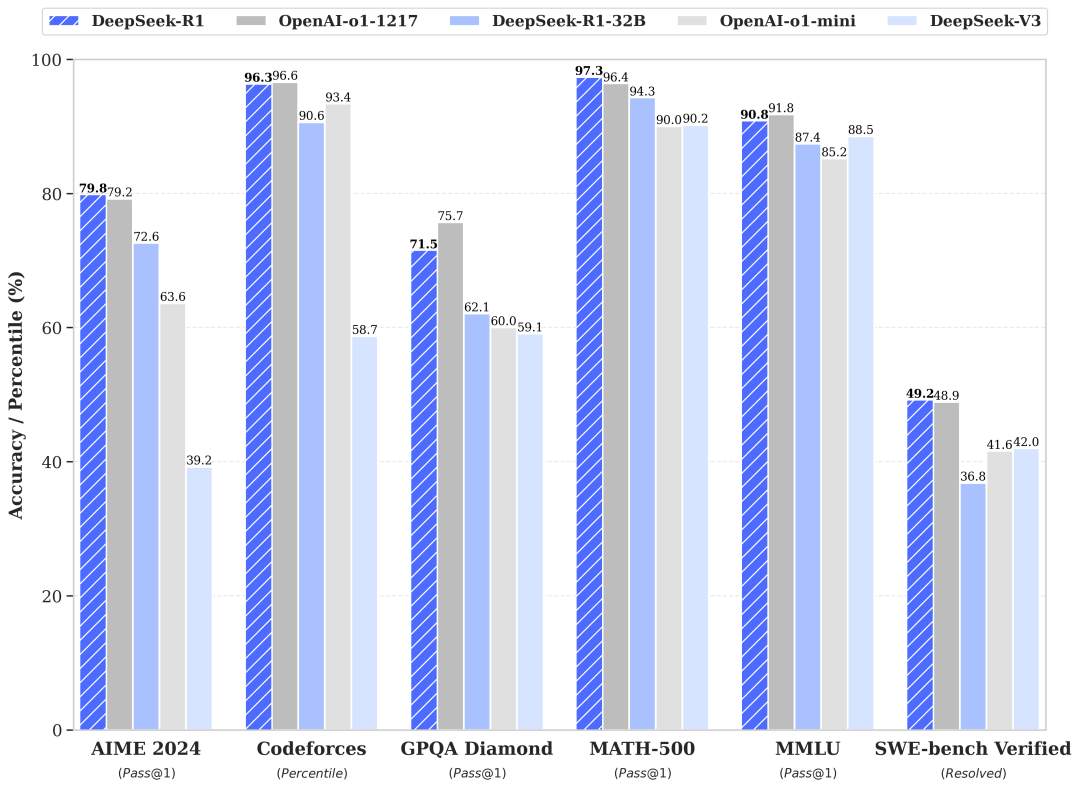 DeepSeek-R1 在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。在数学、代码、自然语言推理等任务上,性能比肩 OpenAI o1 正式版。|来源:DeepSeek
DeepSeek-R1 在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。在数学、代码、自然语言推理等任务上,性能比肩 OpenAI o1 正式版。|来源:DeepSeek
张鹏:DeepSeek-R1 里的模型技术,有哪些创新让你们印象比较深刻?
方汉:技术角度,这次 R1 做了很多技术上的改进,像 DualPipe 算法,像用 PTX 去写通讯之类的,最印象深刻的肯定也是训 R1-Zero 用的 GRPO 这个技术,这是整个 R1 里最核心的东西。
因为 OpenAI 在做 o1 的时候,请了上百个数学博士天天解题,数据非常高质量,但他从来不对外界说怎么做数据。大家也知道很多公司会用 PPO,真正能把 PPO 用得特别好的还是 OpenAI 和 Anthropic。国内大家在 PPO 用不好的前提下,DeepSeek 用 GRPO 的方法非常巧妙,省掉了 Critic Model,后者做起来特别大、特别慢。
通过 GRPO 的方法,可以快速迭代出一批特别高质量的 CoT 数据,这一点特别令人震惊,等于说 OpenAI 自己辛辛苦苦找人花钱做出来的数据,被咣地一下给开源了,而且从结果上来看,它的质量特别好,不逊于 OpenAI 的内部数据。这一点是非常非常革命性的,我们一直认为合成数据比不上人的数据,但是R1 这一次有可能表明,合成数据不比人标的数据差。这给很多人带来了希望,像欧洲、印度、韩国都觉得自己也可以做了。
02
DeepSeek 文笔好,是因为没有好好做产品?
张鹏:一些在硅谷的华人 AI 研究员也说,可能过去海外的大模型对于高质量中文数据没有特别较真过,但 DeepSeek 较真了。方汉你怎么看「大家说 DeepSeek 文笔好」?
方汉:虽然我学的是理科,但我高考作文是满分,所以对古文比较熟,我特别喜欢让大模型写古诗词。在这件事上,现在写的最好的模型实际上是 Claude,也就是说 Claude 的文采比 ChatGPT 要好很多。我觉得还是数据的原因,大家公认 Anthropic 对数据的品位最高,数据做得最好,他们的数据团队规模在语文和写作方面非常强,我猜 DeepSeek 也是类似。
DeepSeek 内部可能有一套方法,可以从现有的数据里面生成质量非常高的语文数据,这是我的猜想。因为请大量顶尖团队比如北大中文系标数据,DeepSeek 未必竞争得过大厂,(靠人工标注数量和质量取胜)逻辑上讲不通。DeepSeek 在不要人干预的情况下,可以用 GRPO 可以生成数学和编程的 CoT 数据,那这些方法能不能用在语文上去生成高质量的语文数据,这是我更相信的一个推断。
另外,我们在做推理模型的时候有个叫 temperature(温度)的参数,如果把这个参数值设得高,模型就开始胡说八道、特别有创意,但也很容易崩。可能因为 R1 的推理能力很强,哪怕把 temperature 加得比一般模型高,也是比较活跃且不容易崩。
03
「被 DeepSeek 的思考过程震撼到了」
张鹏:除了文笔好,很多用户也被 DeepSeek 思考过程的透明和清晰的逻辑打动,R1 是第一家展示思考过程的模型吗?你觉得 OpenAI 为什么不给大家公开思维链?
方汉:我觉得 OpenAI 就是想保守机密,OpenAI 一直认为思维链数据是它最值钱的数据,所以很早就出了一个 term sheet(条款),你要是敢 jail break(越狱)问他 CoT 的问题,他会封你的账号。R1 发布之后,OpenAI 也把 o3-mini 的思维链输出了,但这里是总结版的思维链,结果又被网友骂了,然后现在又正在把总结再去掉。
当然大家没有想到的是 DeepSeek 说,要不我试一下,我也不要中间这个步骤,直接给你强化学习行不行?很长时间大家都觉得中间需要搞一步 SFT,结果 DeepSeek 出来跟你说,我们试了一下,好像不需要也行。
张鹏:因为没有人做出来过,或者没有人按这个方式做出来过。你怎么评价这次 R1 展示的透明的思维链?
 DeepSeek 推测,用户说是别人的提问,很可能是用户自己的提问。|截图来源:DeepSeek App
DeepSeek 推测,用户说是别人的提问,很可能是用户自己的提问。|截图来源:DeepSeek App
方汉:从纯技术的角度,看思维链可以改进你的 prompt。但对于绝大部分用户,不会这么用思维链。
对于用户来说最可怕的体验是,看到 R1 思维链这么严密的推理过程,有点像我们小时候看卡耐基成功学、有点像听一些特别牛的人把他思维方式给你讲一遍,你是会很震撼的。
现在,你目睹了 AI 用一个聪明人、成功学的方法给你推导一个问题,所有人心里都会心生感叹,「这个 AI 真聪明,接近人类智能呢」。我觉得这对产品的推广来说,是一个决定性的心理暗示。
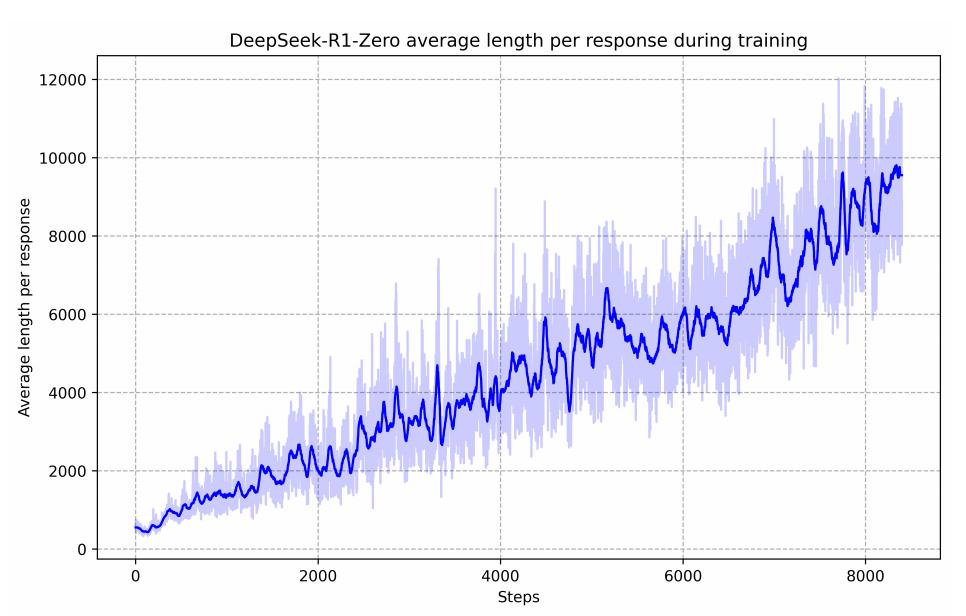 DeepSeek-R1-Zero 的性能轨迹,整个强化学习过程中稳定且持续提升。|截图来源:DeekSeek-R1 技术报告
DeepSeek-R1-Zero 的性能轨迹,整个强化学习过程中稳定且持续提升。|截图来源:DeekSeek-R1 技术报告
张鹏:怎么理解强化学习在 R1 和 R1-Zero 体现出的效果?
方汉:打个不太恰当的比方来类比理解,让一个小孩学乒乓球,先让他看所有高手打乒乓球的视频,但他看完了之后仍然不会打。
这时候有两个方法,一是请国家队队员比如马龙来教他,但绝大多数家庭请不起国家队。怎么办呢?这时候请不起国家队的家庭就想了个办法,让人对着一个洞去打球,打不中就「电」你一下。奖惩机制下,终于这个小孩成了一个绝世高手,但是他这时候还不太懂乒乓球的规则,发球也不标准等等。这时候终于又请了一个教练,告诉小孩得按照什么样的规则打球,让他把规则学会,学会了就出去「大杀四方」,这个逻辑大概是这样。
这里其实有一个问题,刚才大家也聊到了,现在不知道 V3 这个基座模型看没看过高质量的 CoT 数据?但是它后来的激发做得非常成功。我觉得这给了所有「穷人」一个念想,我靠自己「电」自己,也能把自己「电」成高手。这样的话,很多欧洲、印度的公司也可以开始训练这种高质量模型了。
04
更好的模型,并不意味着 AI 应用更好做了
张鹏:方汉,你怎么看它对于 AI 产业站在全球视角比较确定接下来可能带来的影响、冲击和变化是什么?
方汉:大家都说大模型的下一场是 agent,但如果是多 agent 协作的情况,只要有一个 agent 拉胯,最后质量就很差。现在 R1 保证了 agent 智能的下限比较高,很多以前完不成的、比较长、比较复杂的任务,有可能很快就会被解决。比如 AI 编程,原来只能写单个函数,甚至只能写一个文件,现在有了 R1 这样特别强的模型,是不是可以直接把整个工程生成出来,而且交叉地修改、debug?这样就真正成为一些可用的生产力。
对于具体的产品,我觉得所有跟 agent 相关的新的产品模式会快速涌现,而且由于模型是开源的、成本还特别低,很多产品也开始看到了盈利的曙光,因为推理成本下降了,而且能力还上升了。
另外,R1 在数学跟编程任务上表现最好,因为数学和编程是人类用符号来固化思维的两个最显著的领域。相应地,还有科学,比如说像 AlphaFold 做的是蛋白质折叠预测。我认为跟符号化形式相关的、数据比较强的领域,都会带来特别大的效率改善。
张鹏:昆仑万维的产品线会更丰富,这里有没有一些比较具象的思考?经过年初这一波冲击之后,在AI应用上有什么新的启发?
方汉:DeepSeek 不是第一个开源的,但它是开源的模型里面质量最好、最接近 OpenAI 的水平的,这是它出圈的根本原因,这给 AI 应用带来一系列影响。
首先他把一个很高质量的模型的推理成本打低之后,给商业模式带来了更多的可能性,免费类的AI应用会逐渐出现。
第二,降低 AI 应用的门槛是关键。全球能够写好 prompt 人数不会超过 1000 万,所以怎么降低 AI 应用的门槛非常关键。举个例子,最近谷歌 NotebookLM 会爆火,就是因为它极大地降低了应用门槛,不用写 prompt,把 PDF 拖进去,按一个按钮就给你生成播客了。
第三,云计算时代,有一个词叫云原生,是指一些在云计算出现之后才涌现出的云原生公司,这些公司完全是轻资产,所有服务都跑在云上。我觉得 AI 时代的应用也会有类似变化,现在 AI 原生的产品经理其实还不多,大部分人都还在用互联网和移动互联网的思路来做 AI 应用。这是一个痛点,大家都还在摸索。但接下来,产品经理当老大的 AI 公司会越来越多,AI 原生的产品设计也会越来越多。
最后,很多公司现在做了效率类的 AI 应用,但是从互联网跟移动互联网的经验来看,效率产品的增速一定比不过娱乐产品,人类都是喜欢娱乐至死,而娱乐产品其实并不一定需要特别强的 AGI,但是需要特别强的AIGC,所以我认为娱乐产品的发展速度接下来会远远超过 ToB 的效率产品。
张鹏:效率型的工具可能是人类的一部分需求,人类无尽的需求是娱乐,你觉得在娱乐这件事上 2025 年有什么样的东西值得看?在娱乐方面会出现足够让人兴奋的 killer APP 吗?
方汉:人类最喜欢、成本最低、门槛最低的娱乐方式是视频,我们认为视频生成领域一定会涌现出最大的 killer APP,只是不知道是传统的渠道为王、还是新的视频制作平台为王。
大家都知道短视频席卷全球,短剧现在是第二波,也要开始席卷全球,现在就算短视频的成本很低,但是拍一部短剧也要 100 万人民币,所以现在中国每年只能产三四千部短剧。如果我们能够把单部短剧的成本达到 2000 块钱,那么全世界每年可能会有几百万部短剧的产出,这会对整个业界带来非常大的冲击。
打个比方,我没有学过音乐、也五音不全,现在用我们的音乐生成大模型,我可以做很多首歌。同时在成本上,举个例子,我们原来做游戏业务的时候,订购一首音乐平均 5 万块钱左右,现在音乐模型推理成本可能只有几分钱,这就是成本以及门槛的降低。
当一个东西的生产门槛以及成本显著降低,AI内容就会像抖音的短视频作者那样,因为手机摄像头和 4G 的出现,生产出大量短视频内容。但我觉得 2025 年还可能还没有到时间点。现在的视频生成模型虽然已经非常强了,但是还没有到能够取代完整的影视产业链的地步。
 去年底,昆仑万维在美国上线 AI 短剧平台 SkyReels,在全球 AI 娱乐市场做出进一步探索。|来源:昆仑万维
去年底,昆仑万维在美国上线 AI 短剧平台 SkyReels,在全球 AI 娱乐市场做出进一步探索。|来源:昆仑万维
张鹏:今年的视频生成领域还会像 2024 年一样快速迭代吗?
方汉:对。2023 年春晚已经有 AIGC 的视频出现了,但那时候还比较原始,现在比如字节最新发的 OmniHuman 视频质量就非常好了,大家都在飞速演进。
而且大家也不要迷信 OpenAI,Sora 已经被第三方的、闭源的、开源的模型迅速追上,也就是说 OpenAI 在图像生成和视频生成领域起了个大早,赶了个晚集,现在无论开源还是闭源,都有跟 Sora 比起来有很强的竞争力的视频生成模型。而且开源生成模型有更好的生态,对长尾需求的满足也会更好,最终基于此的商业模式也会最多。
张鹏:你怎么看 chatbot(聊天机器人)这种类型的产品?娱乐陪伴型的 chatbot 是一种,ChatGPT 也是一种 chatbot,这种类型的产品未来还会是一个标准形态吗?还是一个过渡形态,接下来要探索新的东西?
方汉:我认为它只是一个原始形态。就像最早 QQ 刚出来的时候,大家都是用键盘打字输入到 QQ 对话框,但是到微信出来的时候,我妈妈从来不给我打字,都是直接发语音,甚至一言不合就开视频。所以我认为现在的 chatbot 只是一个很早期的形态,像 GPT-4o 把多模态像语音、视频引入 chatbot,是自然的过程、逐渐演进的。
就像早期的互联网有一个产品叫 MUD(Multi-User Dialogue,多用户对话),从文字 MUD(文字冒险游戏)又衍生出来了两个重量级的娱乐游戏产品,一个是叫大话西游,一个是叫魔兽世界。我认为现在的 chatbot 演化的终极形态有可能是一个类似于元宇宙的、虚拟多媒体的交互形态。
05
DeepSeek 冲击波下,英伟达还好吗?
张鹏:R1,包括 V3 在保证模型效果的情况下,实现成本相对比较低。这是为什么?
方汉:由于美国的禁运,我们能够得到的算力资源是有限的。这样会倒逼所有中国团队在软件优化上倾注比美国同行更多的精力。像 DeepSeek 团队做的那样,比如实现了 FP8 混合精度的训练,压缩显存占用来让训练速度更快。在训练加速上,他们做出了卓越的努力,也获得了丰厚的回报,这不是只在 R1 里才有体现,之前训练 V2 也已经展现出这个实力。
张鹏:我再追问一下,DeepSeek-R1 出来之后,紧接着英伟达来了个近年来最大跌幅,有了更高效率训练出来的模型,大家对英伟达的预期怎么样?
方汉:我的观点是,对英伟达来说,短期利空、中期利好、长期利空。
尽管 OpenAI 和软银的「星际之门」号称要投资 400 亿美金,买的都是英伟达的训练卡,但是 DeepSeek 现在把训练成本打下去之后,美国人也不能自己花 100 亿美金,来训练中国人只要花 10 亿美金的任务。之前一路高涨的股价,是因为所有投资者都是赌他的训练卡,所以我觉得短期利空英伟达。
中期利好是什么原因呢?如果仔细看 DeepSeek 的技术报告,他们的所有的推理优化都是基于英伟达的 CUDA 平台,比他们更懂英伟达 CUDA 平台的也没有几家。一旦 DeepSeek 把特别好的模型的推理成本打下来之后,模型就更容易商品化,之后整个市场规模会变大。所以英伟达的推理卡在中期一定会卖得非常好。
长期利空是当大模型开始固化下来,英伟达推理卡的壁垒就保不住了,第三方厂商的机会就开始来了。像美国有家叫 Groq 的公司,中国最近也有数十家芯片公司宣布支持 DeepSeek 模型部署。
06
关于 DeepSeek,What's Next?
张鹏:如果你是梁文峰,你觉得 DeepSeek 接下来下一步的重心会是什么?
方汉:我觉得 DeepSeek 是一个非常轻商业化的公司,完全是靠技术力破圈,而不是靠推广破圈。很多人愿意跟着梁文峰总干的一个原因是因为他纯粹,到现在他还在手敲代码。我觉得一个公司的 CEO 还在手敲代码的时候,这个公司一定是一个非常技术向的公司。
他们的服务器扛不住这件事情,他肯定会花心思去解决,但是至于流量能不能接得住?我个人觉得不是他关心的重点。而且只要 DeepSeek 的技术继续迭代,还会有泼天的流量,这也不是个问题。
当务之急肯定还是怎么样招更好的、志同道合的人进到他的团队,继续快速迭代,因为从 V2 出的 MLA、MTP,再到 R1 的 GRPO 出的 Dualpipe,你可以看到里面别出心裁的技术革新层出不穷,说明他们是一支非常有战斗力的团队,人才密度很高。只要他继续保持人才密度,不盲目扩张,还会继续在 AGI 的道路上带来更多惊喜。
张鹏:你觉得他接下来这个产品节奏怎么样?到底会用多快的速度发哪个版本的什么?
方汉:我认为 DeepSeek 接下来首先是泛化数据,现在的数据主要是编程跟数学,要把数据泛化到理科、文科,OpenAI 原来是雇数学博士,现在据说开始雇生物博士去构造数据。我觉得现在 DeepSeek 有了更好的资源也一定会在构造数据上做出更多的探索。
第二,它也会泛化训练方法到多模态以及不同的领域。今天看到香港中文大学的一篇论文,已经有人把 o1 的训练方法泛化到图像生成上了,所以我觉得这两个方向应该都有很大的空间可以挖。
张鹏:某种程度上很多人都看到所谓叫泼天的流量,但其实未必跟他站在同样的视角,他可能看到的是服务器压力很大,下一个模型还要再超越,更新的速度还要更快,开源的持续价值交付……在这个世界打开一扇门的时候,我要能够探索一个更大的天地,这里反而需要花更多的时间聚焦在技术上。怎么在不商业化的情况下把这事做好,反而是更难的挑战。
本文转载自极客公园,内容有删减
相关文章
- 和利时成功入选国家2024年实数融合典型案例名单
- 行业洞察|德勤研究:高科技企业应如何做好全球化治理?
- 支持平台部署!金山云完成基于国产芯片的DeepSeek满血版适配
- 国科础石“智能算法安全验证平台”荣获2024人工智能应用场景创新挑战赛一等奖
- 和利时闪耀2025CAIMRS!硬核科技斩获五大奖项,引领智造新时代
- 中科创达滴水OS智舱荣登人工智能全景赋能典型案例榜单
- 再获突破!移远通信5G RedCap模组RG255C-GL通过北美两大运营商认证,加速全球商用进程
- 瑞数信息实力入围《2024中国数据安全企业全景图》
- 「新质卓见」系列直播,全方位解析数字化应用的洞察&实践
- 美团上线“明厨亮灶”专区,多举措全国推广“阳光厨房”
- 排行